Slope One is a family of algorithms used for collaborative filtering, introduced in a 2005 paper by Daniel Lemire and Anna Maclachlan[1]. Arguably, it is the simplest form of non-trivial item-based collaborative filtering based on ratings. Their simplicity makes it especially easy to implement them efficiently while their accuracy is often on par with more complicated and computationally expensive algorithms[1][2]. They have also been used as building blocks to improve other algorithms[3][4][5][6][7][8].
[edit]Item-based collaborative filtering of rated resources and overfitting
When ratings of items are available, such as is the case when people are given the option of ratings resources (between 1 and 5, for example), collaborative filtering aims to predict the ratings of one individual based on his past ratings and on a (large) database of ratings contributed by other users.
Example: Can we predict the rating an individual would give to the new Celine Dion album given that he gave the Beatles 5 out of 5?
In this context, item-based collaborative filtering [9][10] predicts the ratings on one item based on the ratings on another item, typically using linear regression (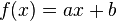 ). Hence, if there are 1,000 items, there could be up to 1,000,000 linear regressions to be learned, and so, up to 2,000,000 regressors. This approach may suffer from severe overfitting[1] unless we select only the pairs of items for which several users have rated both items.
). Hence, if there are 1,000 items, there could be up to 1,000,000 linear regressions to be learned, and so, up to 2,000,000 regressors. This approach may suffer from severe overfitting[1] unless we select only the pairs of items for which several users have rated both items.
A better alternative may be to learn a simpler predictor such as 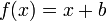 : experiments show that this simpler predictor (called Slope One) sometimes outperforms[1] linear regression while having half the number of regressors. This simplified approach also reduces storage requirements and latency.
: experiments show that this simpler predictor (called Slope One) sometimes outperforms[1] linear regression while having half the number of regressors. This simplified approach also reduces storage requirements and latency.
Item-based collaborative is just one form of collaborative filtering. Other alternatives include user-based collaborative filtering where relationships between users are of interest, instead. However, item-based collaborative filtering is especially scalable with respect to the number of users.
[edit]Item-based collaborative filtering of purchase statistics
We are not always given ratings: when the users provide only binary data (the item was purchased or not), then Slope One and other rating-based algorithm do not apply. Examples of binary item-based collaborative filtering include Amazon's item-to-item patented algorithm[11] which computes the cosine between binary vectors representing the purchases in a user-item matrix.
Being arguably simpler than even Slope One, the Item-to-Item algorithm offers an interesting point of reference. Let us consider an example.
Sample purchase statistics
Customer
Item 1
Item 2
Item 3
| John |
Bought it |
Didn't buy it |
Bought it |
| Mark |
Didn't buy it |
Bought it |
Bought it |
| Lucy |
Didn't buy it |
Bought it |
Didn't buy it |
In this case, the cosine between items 1 and 2 is:
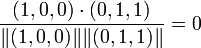 ,
,
The cosine between items 1 and 3 is:
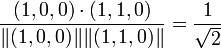 ,
,
Whereas the cosine between items 2 and 3 is:
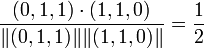 .
.
Hence, a user visiting item 1 would receive item 3 as a recommendation, a user visiting item 2 would receive item 3 as a recommendation, and finally, a user visiting item 3 would receive item 1 (and then item 2) as a recommendation. The model uses a single parameter per pair of item (the cosine) to make the recommendation. Hence, if there are n items, up to n(n-1)/2 cosines need to be computed and stored.
[edit]Slope one collaborative filtering for rated resources
To drastically reduce overfitting, improve performance and ease implementation, the Slope One family of easily implemented Item-based Rating-Basedcollaborative filtering algorithms was proposed. Essentially, instead of using linear regression from one item's ratings to another item's ratings (), it uses a simpler form of regression with a single free parameter (). The free parameter is then simply the average difference between the two items' ratings. It was shown to be much more accurate than linear regression in some instances[1], and it takes half the storage or less.
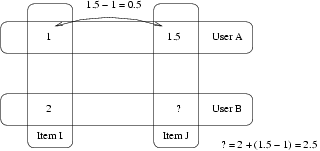
Example:
- User A gave a 1 to Item I and an 1.5 to Item J.
- User B gave a 2 to Item I.
- How do you think User B rated Item J?
- The Slope One answer is to say 2.5 (1.5-1+2=2.5).
For a more realistic example, consider the following table.
Sample rating database
Customer
Item 1
Item 2
Item 3
| John |
5 |
3 |
2 |
| Mark |
3 |
4 |
Didn't rate it |
| Lucy |
Didn't rate it |
2 |
5 |
In this case, the average difference in ratings between item 2 and 1 is (2+(-1))/2=0.5. Hence, on average, item 1 is rated above item 2 by 0.5. Similarly, the average difference between item 3 and 1 is 3. Hence, if we attempt to predict the rating of Lucy for item 1 using her rating for item 2, we get 2+0.5 = 2.5. Similarly, if we try to predict her rating for item 1 using her rating of item 3, we get 5+3=8.
If a user rated several items, the predictions are simply combined using a weighted average where a good choice for the weight is the number of users having rated both items. In the above example, we would predict the following rating for Lucy on item 1:
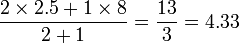
Hence, given n items, to implement Slope One, all that is needed is to compute and store the average differences and the number of common ratings for each of the n2 pairs of items.
[edit]Algorithmic complexity of Slope One
Suppose there are n items, m users, and N ratings. Computing the average rating differences for each pair of items requires up to n(n-1)/2 units of storage, and up to m n2 time steps. This computational bound may be pessimistic: if we assume that users have rated up to y items, then it is possible to compute the differences in no more than n2+my2. If a user has entered x ratings, predicting a single rating requires x time steps, and predicting all of his missing ratings requires up to (n-x)x time steps. Updating the database when a user has already entered x ratings, and enters a new one, requires xtime steps.
It is possible to reduce storage requirements by partitioning the data (see Partition (database)) or by using sparse storage: pairs of items having no (or few) corating users can be omitted.
from:http://en.wikipedia.org/wiki/Slope_One#Open_source_software_implementing_Slope_One






相关推荐
基于奇异值分解的Slope One算法,林德军,孟祥武,Slope One算法是一种基于项目的协同过滤推荐算法,利用线性回归模型来预测评分。Slope One算法在数据稀疏的情况下推荐效果不好,而矩阵
Slope One算法是一种基于项目的协同过滤推荐算法,它对项目属性内和属性间依赖耦合关系的考虑较为欠缺,推荐效果并不理想。基于此,提出一种基于耦合关系的加权Slope One算法。该算法构造了项目属性耦合关系模型和...
针对因Slope One算法没有考虑相似性,而导致个性化推荐准确率不高的问题,提出了一种基于用户相似性的加权Slope One算法(BUS weighted Slope One算法)。通过先评定用户活跃度,筛选出活跃用户,然后依据项目间相似...
SlopeOne算法
一种基于机器学习的加权SlopeOne算法改进.doc
Slope One算法在Hadoop平台的改进实现,鲍崴崴,苏放,近年来电子商务网站对精确投放广告的需求日益加大,协同过滤的推荐算法作为一种力求准确推测用户需求的方案,应用越来越普遍。本
一种改进的Slope One推荐算法,柴华,刘建毅,Slope One算法是一种简单高效的典型协同过滤推荐算法,数据稀疏性是影响其推荐准确率的主要问题。为了克服该问题,本文提出了一种改
文档基于Slope one算法的电影推荐系统电影推荐系统提取方式是百度网盘分享地址
程序以matlab语言编写,包括了Pearson相似度、UserCF、ItemCF、slope one算法、TopN推荐、MAE、RMSE、准确度、覆盖率等常用算法代码.zip数学建模大赛赛题、解决方案资料,供备赛者学习参考!数学建模大赛赛题、解决...
针对传统协同过滤算法存在冷启动、数据稀疏、运行效率低下等问题,分析了较传统协同过滤算法更加高效准确的Slope One算法的优点、原理及流程。针对Slope One算法未考虑用户兴趣变化和用户相似性这两方面的问题,提出...
Slope One 算法基于简单的线性回归模型,通过减少响应时间和维护难度,显著提高了推荐性能。然而 Slope One 算法没有考虑用户内部的关联,同等地使用...在 MovieLens数据集上的实验结果表明,该算法与原 Slope One算法相比
该算法使用slope-one算法计算出来的评分预测值来填充评分矩阵中的未评分项目,然后在填充后的用户—项目评分矩阵上通过基于用户的协同过滤方法给出推荐。利用slope-one算法计算出来的评分预测值作为回填值,既能降低...
基于差分隐私的Slope One协同过滤推荐算法,王辉,何杰,Slope One算法是一种简洁高效且推荐精度高的协同过滤推荐算法,然而其很难提供一个严格的隐私保证。潜在攻击者可以通过观察用户的推
针对Slope One算法存在预测精度依赖于用户对待预测项目的评分数量的缺陷,提出了一种基于项目属性相似度和MapReduce并行化的Slope One算法.首先计算项目间的属性相似度,并将其与Slope One算法相融合以提高预测精度...
NULL 博文链接:https://coderplay.iteye.com/blog/468623
其次在聚类分析的基础上,利用Slope One算法预测填充生成的相似用户集下的用户评分矩阵;最后采用混合协同过滤算法对填充后的用户评分矩阵进行最近邻搜索,从而得到预测评分,产生推荐结果。对比实验结果表明,提出...
在 Movielens 数据集上利用按照时间戳排序后划分的测试集进行实验,结果表明 Simplified Slope One 算法对评分预测的准确性与原 Slope One 算法接近,但时间复杂度和空间复杂度均低于原 Slope One 算法,更适合在...
slope one 算法python实现
Daniel Lemire 写的介绍Slope one 算法的lecture。 想深入学习slope one的可以看看
该代码是一个完整的slope one 案例,里面有main函数和初始化值,可以直接运行观测结果,代码结构清晰,方便用户修改或研究使用